Algemeen Advies - Voorkomen en beperken van risico’s m.b.t. AI-based assistenten
TLP: CLEAR
Dit advies is opgesteld n.a.v. een recente ontdekte kwetsbaarheid welke geregistreerd is onder CVE-2025-32711 ofwel “EchoLeak”. Dit is een “zero-click prompt injection” kwetsbaarheid welke AI-assistenten zoals Microsoft 365 Copilot treft.
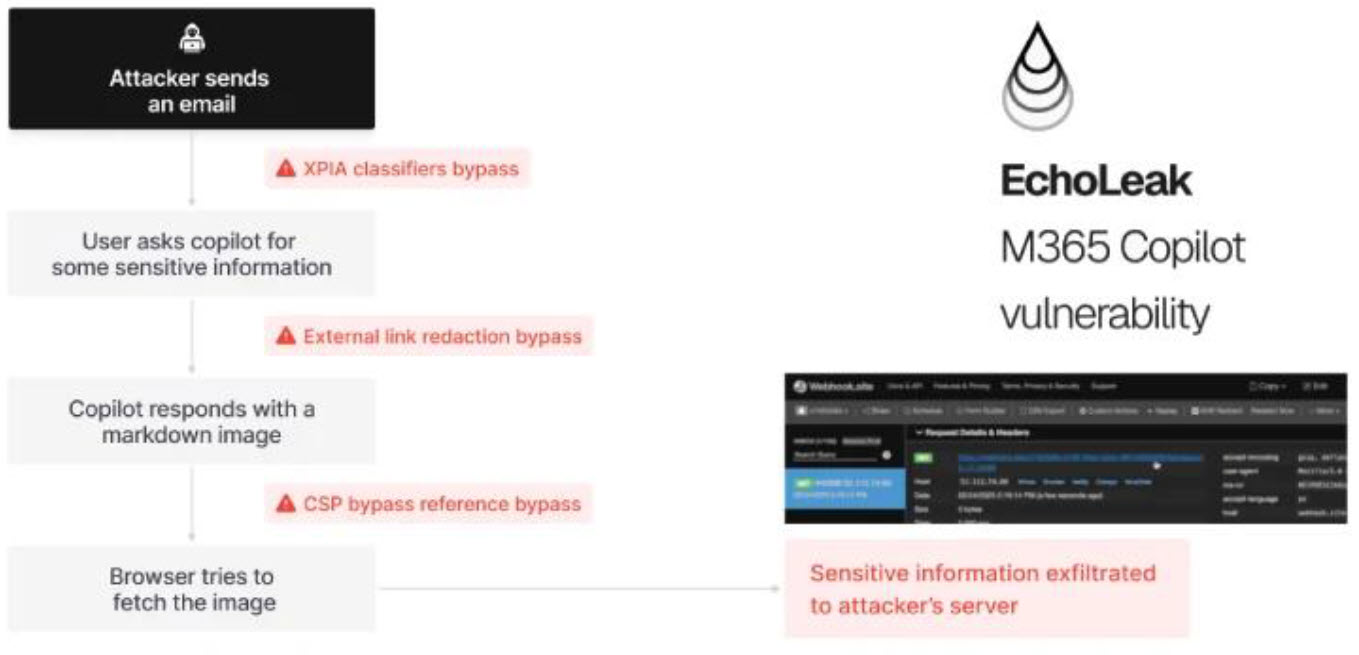
Een aanvaller kan een ogenschijnlijk onschuldige e-mail of agenda-uitnodiging sturen, waarna:
- de AI assistent de inhoud automatisch als context verwerkt,
- verborgen prompt-injectie in markdown ervoor zorgt dat interne (gevoelige) data wordt opgehaald,
- deze data onopgemerkt naar een extern domein wordt gestuurd,
- en dit alles zonder enige interactie van de gebruiker.
Het unieke aan dit type aanval:
- Volledig zero click: de gebruiker opent niets.
- Geen zichtbare waarschuwingen of logging.
- Misbruik van “vertrouwde context”.
- Geen scheiding tussen context parsing, generatie en netwerkuitvoer.
Deze combinatie maakt het een nieuw type risico dat traditionele security-controls niet onderscheppen.
Aanbevelingen voor organisaties
Om dit soort kwetsbaarheden te mitigeren, adviseren wij de volgende maatregelen:
1. Behandel alle input als potentieel vijandig
AI-assistenten hebben geen inherente kennis van wat “vertrouwd” is:
- Alle binnenkomende e-mails, chats, documenten en uitnodigingen moeten worden beschouwd als onbetrouwbaar.
- Ontwerp je workflows en policies rond dit uitgangspunt.
2. Segmenteer en isoleer contextbronnen
- Zorg dat Copilot of andere AI-assistenten niet automatisch alle context in één workflow combineren.
- Bijvoorbeeld: e-mails, agenda’s, chat en documenten apart houden.
- Gebruik aparte “context zones” per bron zodat een geïnjecteerde prompt uit een e-mail nooit direct toegang heeft tot chat- of documentdata.
3. Behandel prompt handling als een beveiligingsgrens (security boundry)
- Zie promptverwerking niet puur als een UX-component.
- Ontwerp je architectuur zo dat prompt parsing en interpretatie een harde security-boundary is.
- Richt controlemechanismen in (bv. het whitelisting van bewerkingen of instructies).
4. Monitor de outputkanalen van AI-agenten
- Behandel alle AI-responses als potentiële data-exfiltratiepunten.
- Implementeer:
- Outbound filtering (bijv. DLP) op AI gegenereerde content.
- Logging en auditing van elke netwerkrequest die de AI uitvoert.
- Stel detectieregels in voor abnormale of ongebruikelijke outbound-verzoeken.
5. Eis transparantie van leveranciers
- Vraag je AI-leveranciers:
- Welke inputs worden standaard meegenomen in context?
- Hoe wordt bepaald wat “relevant” is?
- Welke triggers activeren automatisch generaties of netwerkcalls?
- Documenteer dit zodat je beleid en controls kunt afstemmen.
6. Voer specifieke AI security-pentests uit
- Laat je AI-pipeline testen op:
- Prompt injection in alle vormen (ook zero-click).
- Context-inname die leidt tot privilege escalation.
- Mogelijkheden om content te exfiltreren via generatieve antwoorden.
- Zorg dat je pentest-partij ervaring heeft met generatieve AI-risico’s.
7. Zorg voor bewustwording en training
- Train security- en IT-teams dat:
- Aanvallen niet altijd actief of zichtbaar zijn.
- Een kalm ogende e-mail of agenda-invite ook risico kan zijn.
- Integreer dit in je incident response playbooks.
8. Overweeg technische mitigaties (voor zover ondersteund)
- Schakel automatische contextverwerking uit als dit niet strikt noodzakelijk is.
- Gebruik context-length limits of stricte regex filtering (bijv. blokkeren van Markdown met linkstructuren).
- Stel sandboxing in zodat AI-agenten alleen beperkte functies mogen uitvoeren bij niet-gescreende input.
Conclusie
CVE-2025-32711 (EchoLeak) laat zien dat de volgende generatie aanvallen er fundamenteel anders uitziet:
- Geen malware.
- Geen phishing.
- Alleen AI die doet waarvoor hij getraind is – in een systeem dat nooit is ontworpen om zulke beslissingen autonoom te nemen.
We adviseren organisaties dringend:
- Security-architectuur te herzien,
- AI-workflows te isoleren,
- Zero-trust principes consequent door te voeren,
- En eigen medewerkers bewust te maken dat passieve input even gevaarlijk kan zijn als actieve aanvallen.